BASICS C++
---------- C VS C++ ----------

-- SOLID: always follow this principle while executing any program.
S – Single Responsibility Principle (SRP)
O – Open Closed Principle (OCP)
L – Liskov Substitution Principle (LSP)
I – Interface Segregation Principle (ISP)
D – Dependency Inversion Principle (DIP)
-- Class: Its the prototype built to represent a property of the group.
Default constructor, Parameterized constructor, copy constructor assignment operator overloading constructor are the ways to instantiate the object.
Facts on class :
- sizeof an empty class is 1byte
- default constructor or default things provided from compiler is public by default.
Facts on Constructor :
- The compiler provides default constructor, copy constructor, assignment constructor and destructor.
- you can overload the constructor. that is called as parameterized constructor. But, when the parameterized constructor is defined from user, we cannot use the default constructor provided from compiler. It has to be defined in mandatory.
Return value for Constructor and destructor :
The The reason the constructor doesn't return a value is because it's not called directly by your code, it's called by the memory allocation and object initialization code in the runtime.
Destructor : cannot have arguments and no return type. It is used for de-allocation and clean-up.
Destructor : cannot have arguments and no return type. It is used for de-allocation and clean-up.
Static Constructor:
Static constructors exist in C# and Java and not in c++.
They are used to initialize static members of a class.
The runtime executes them before the class is first used.
They are used to initialize static members of a class.
The runtime executes them before the class is first used.
Copy Constructor: Passing the object of the same class in the constructor arguments. It can be private.
Below is the way to avoid the copy constructor and assignment operator use in the class construction.
RTCQNX(const RTCQNX &rtcQnx) = delete;
RTCQNX& operator = (const RTCQNX &rtcQnx) = delete;
Copy constructor is called when a new object is created from an existing object, as a copy of the existing object. test t1 = t2; not test t1; t1 = t2(calls assignment). Assignment operator is called when an already initialized object is assigned a new value from another existing object.
A ob1(ob2) ==> ob2 is passed as param . A(const &ob) { this.x = ob.x} so, here the passed param is rvalue and called object. lvalue is the calling object.
Shallow Copy Vs Deep Copy :
A shallow copy of an object copies all of the member field values. The pointer will be copied.
The field in both the original object and the copy will then point to the same dynamically allocated memory.
Ex: default copy constructor, assignment operator from compiler.
A deep copy copies all fields, and makes copies of dynamically allocated memory pointed to by the fields.
Ex: User defined copy constructor. here, instead of assigning the direct pointer, assign only value to it.
In user defined copy constructor, if you dont implement user defined copy constructor and still assign one object to another, then both the objects will be pointing to same memory region.
The default copy constructor and assignment operator make shallow copies.
class test{int *ptr; test(){ptr = new int; ptr[0] = 9;}
The difference between copy constructor and assignment constructor is that in copy constructor the default constructor is not called. Whereas in assignment, the default will be called.
Friend function: A friend can be a function, function template, or member function, or a class or class template, in which case the entire class and all of its members are friends.
class Node {
// Now class LinkedList can access private members of Node
friend class LinkedList;
void printNode(){ --- }; friend void printNode(); };
Friend class is frequently used, in case of the operator overloading functions.
Inline function: compiler places a copy of the code of that function at each point where the function is called at compile time. It creates a faster code and smaller executables. when functions are small, and the code is called often, inline is used.
When we should avoid the use of inline?
- We should not use functions that are I/O bound as inline functions.
- When large code is used in some function, then we should avoid the inline.
- When recursion is used, inline function may not work properly.
- One point we have to keep in mind, that inline is not a command. It is a request. So we are requesting the compiler to use inline functions. If the
compiler decides that the current function should not be an inline function, it can convert it into normal function.
-- Macro Vs Inline:
The basic difference between inline and macro is that an inline functions are parsed by the compiler whereas, the macros in a program are expanded by preprocessor.
A function that is inline can access the members of the class, whereas, a macro can never access the members of the class.
this: a pointer which holds the address of an object.
static:
A static member function can only access static data member. They do not have access to the this pointer of the class. Other data members and functions are accessed using class name
Ex: classname::<static funtion name/data member>
Static data members can be accessed from main and any other functions just like normal data member of class. A static data member is shared by all objects of the class. one copy is maintained.
Static function in C : These are the special functions which exposes the scope to its own object file. So, it is one of the technique to avoid the extern usage from outside world via interface.
Return value optimization
In the context of the C++ programming language, return value optimization (RVO) is a compiler optimization that involves eliminating the temporary object created to hold a function's return value.
Object: Instance of the class representing the unit of class.
STRUCTURE:
STRUCTURE:
-- structure: if you want to pass & receive more than one variable, structure is a good option.
The main differences between classes and structures, is that class members default to private, whereas structure members default to public.
The main differences between classes and structures, is that class members default to private, whereas structure members default to public.
-> private structure in C:
Structure defined in .c file and not exposing in the header will achieve the private.
-> Structure padding is a known problem. padding ==> aligning of data members in the memory layout of the machine. This can be solved in 3 different solutions
a. Define the struct members in the decreasing order of the variable size. Varies on machine 32/64
b. #pragma pack(1) // To force compiler to use 1 byte packaging . Here, programmer should be aware of packing size.
c. __attribute__((packed)); // Attribute informing compiler to pack all members
d. Bit field in struct members helps to tell the compiler to allocate bit provision. int a:2 ==> allows only 2 bit to be modified in the byte structure
while passing the pointer to a structure in the function, it is treated as a pass by value. Pass the double pointer, to pass as reference. Ex: void addNode in linkedlist.
struct vs union:
A struct is a block of memory that stores several data objects, where those objects don't overlap. A union is a block of memory that stores several data
objects, but has only storage for the largest of these, and thus can only store one of the data objects at any one time.
In C++11, no need of typedef. we can directly call the struct name. Ex: struct node {} -> node *head
Structures limitations in C :
No Data Hiding: C Structures do not permit data hiding. Structure members can be accessed by any function, anywhere in the scope of the Structure.
Functions inside Structure: C structures do not permit functions inside Structure
Static Members: C Structures cannot have static members inside their body
Access Modifiers: C Programming language do not support access modifiers.
Construction creation in Structure: Structures in C cannot have constructor inside Structures.
-- OOPS:
Inheritance: Capability to derive / inherit the properties & characteristics from the other class.
Polymorphism: The ability of a message to be displayed in more than one form.
compile time polymorphism /Static binding : Operator / function Overloading.
Run time polymorphism /late binding/ Dynamic binding : Virtual functions in overriding.
Overloading:
Function Overloading:
Functions can be overloaded by change in number of arguments or/and change in type of args.
An overloaded method may or may not have different return types. But return type alone is not sufficient for the compiler to determine which
method is to be executed at run time. Means if 2 func have same type and arg list but change in return type is not considered as overloaded
functions.
method is to be executed at run time. Means if 2 func have same type and arg list but change in return type is not considered as overloaded
functions.
Operator overloading: (:: * . ?: cannot be overloaded)
Example: Complex operator + (Complex const &obj) {
Complex res; res.real = real + obj.real; return res; }
New and delete operator can also be overloaded with variable no. of args.
Ref: https://www.geeksforgeeks.org/overloading-new-delete-operator-c/
Overriding:
Functions: Derived Function is called, and the base class function is ignored.(overrided inheritance)
Reference: Using base pointer, u can call the derived object and invoke the function of child class, provided base class function is virtual.
Virtual functions : ensure that the correct function is called for an object, regardless of the type of reference (or pointer) used for function call.
To stop overriding of functions for further classes, dont use the virtual keyword (non-virtual).
If you make the method non-virtual, derived classes cannot override the method. However, in C++03 a class cannot override a method from a
base class, and also prevent further derived classes from overriding the same method. Once the method is virtual, it stays virtual.
To stop further inheritance in the class. inherit it as virtual in the derived class.
Vtable: To accomplish late binding, the compiler creates this vtable table for each class that contains virtual functions and for the class derived from it. vtable is created for each class, and has entry of each virtual functions. The compiler places the addresses of the virtual functions for that particular class in "vtable".
VPointers: vpointer is just another class member added by the compiler and increases the size of every object that has a vtable by sizeof(vpointer).
Vtable is in the class level and vpointer in the object level.
Virtual Destructor: Ensures the chronological order of destruction from the derived to the base class.
Virtual Constructor: the constructor cannot be virtual, because when a constructor of a class is executed there is no virtual table in the memory, means no virtual pointer defined yet.
Virtual Constructor: the constructor cannot be virtual, because when a constructor of a class is executed there is no virtual table in the memory, means no virtual pointer defined yet.
Abstraction: Providing only essential information about the data to the outside world, hiding the background details or implementation.
Concrete class: class with no pure virtual functions and can be instantiated.
Abstract Class: Class without any implementation is refer as abstract class. We cannot create objects of abstract classes. But can create a reference pointer.
A pure virtual function is implemented by classes which are derived from a Abstract class.
1) A class is abstract if it has at least one pure virtual function.
2) We can have pointers and references of abstract class type.
3) If we do not override the pure virtual function in derived class, then derived class also becomes abstract class.
4) An abstract class can have constructors.
// TO-DO : Class association for abstract class. Link ASM questions
Implementation:
In order to achieve abstract mechanism, better create a new class header file with function and include this header and accept in other class (base) constructor parameter. Then call the respective function.
This is the perfect mechanism to achieve, instead of making the base class as abstract. as we couldnot create the object of it.
Ex: TimeIListener is abstract with PVF onTimeout=0. Timer includes this header and accepts the listener object as the parameter in constructor. Gyro and Diag are 2 different classes, which inherits Itimelistener and implements the ontimeout. And declares the timer object ans pass(*this). In Timer, onAction, this->onTimeout will be called.
Encapsulation: Wrapping/Binding the data and functions together.
Access specifiers.
-- Storage Class:
Auto(defines the local scope. auto in C was a (superfluous) way of specifying a local variable. In C++11, auto is now used to automatically derive the type of a
value/expression.)
register(local variables that should be stored in a register instead of RAM),
static(instead of creating and destroying it each time),
extern(give a reference of a global variable that is visible to ALL the program files),
mutable(applies only to const objects. It allows a member of an object to override const member function. A mutable member can be modified by a const member function)

-- Qualifiers VS Modifiers :
Modifier : Data Type Modifiers are keywords used to change the properties of current properties of data type. -- long, short, unsigned, signed
Qualifiers : The keywords which are used to modify the properties of a variable are called type qualifiers.
const, volatile(When a variable is defined as volatile, the program may not change the value of the variable explicitly. But, these variable values might keep on changing without any explicit assignment by the program. These types of qualifiers are called volatile.) The volatile keyword is intended to prevent the compiler from applying any optimizations on objects that can change in ways that cannot be determined by the compiler.
Ex: of the compiler optimization is seen in (allocation + post increment) combination.
Ref: https://www.geeksforgeeks.org/understanding-volatile-qualifier-in-c/
-- POINTERS & REFERENCE :
-- Pointers: It is a variable that holds memory address of another variable.
A pointer needs to be dereferenced with * operator to access the memory location it points to.
Null pointer ( returns val 0). you can increment / decrement /compare the pointer.
Array is also considered as pointer. Array of pointers. Double pointer / pointer to a pointer.
passing pointer to a function. Ex: *p = 0 is same as *p = NULL
-> we can declare and initialize pointer at same step or in multiple line.
-> A pointer can be re-assigned. This property is useful for implementation of data structures like linked list, tree, etc.
-> A pointer has its own memory address and size on the stack
-> Pointer can be assigned NULL directly
-> double pointers are allowed
-> Various arithmetic operations can be performed on pointers. Ex: *p = arr[0] -> p++ ==> arr[1]
-> you cannot pass pointer as the param for copy constructor
-- References: Is an alias, that is, another name for an already existing variable. A reference, like a pointer, is also implemented by storing the address of an object.
-> Never return a reference of a local variable. As reference is bound to temporary object, it takes care of out of lifetime var.
-> we should declare and initialize references at single step.
-> a reference cannot be re-assigned, and must be assigned at initialization.
-> reference shares the same memory address (with the original variable) but also takes up some space on the stack.
-> Slicing: copying the derived object to base object - extra members fall away. To avoid slicing, use the reference or const reference.
-> Referrence cannot be assigned NULL directly
-> double referrence is not possible
-> Use referrence for "function parameters and return types"
-> you need to pass reference for the param in copy constructor
Pass by Pointer V/S Pass by Reference :
Both give the same results. the way we pass the arguments differs.
Pass by pointer-> fun(&a, &b)==> fun(int *a, int *b)
Pass by reference-> fun(a,b)==> fun(int &a, int &b)
Ref: https://www.geeksforgeeks.org/pointers-vs-references-cpp/
-- POINTERS Out Of Scope :
There are 4 types of pointer, which are classified based on the way, they go out of scope.
Dangling , void, NULL, wild pointers. https://www.geeksforgeeks.org/dangling-void-null-wild-pointers/
Dangling : A pointer pointing to the memory location which is deleted / freed / the variable which goes out of scope.
Void : A pointer that points to some data location in storage, which doesnot have any specific data.
NULL : A pointer, which is pointing to nothing.
Wild : A pointer not initialized, not even NULL.
-- CONST & POINTERS:
A non-const pointer can be redirected to point to other addresses.
A const pointer always points to the same address, and this address can not be changed.
int *const ptr2 = &value; // ptr2 points to an "int", so this is a const pointer to a non-const value.
Here, you can change the value variable, not via ptr.
But, you cannot change the pointer to ptr = &anotherValue.
Pointer, always points to the same address
A pointer to a non-const value can change the value it is pointing to. These can not point to a const value.
int value = 5; // value is not constant
const int *ptr = &value; // this is still okay
A pointer to a const value treats the value as const (even if it is not), and thus can not change the value it is pointing to.
const int value = 5;
const int *ptr = &value; // this is okay, ptr is a non-const pointer that is pointing to a "const int"
*ptr = 6; // not allowed, we can't change a const value
-- SMART POINTERS:
Ref : https://www.geeksforgeeks.org/smart-pointers-cpp/
There are 4 different smart ptr's - auto_ptr, unique_ptr, shared_ptr, weak_ptr
- auto_ptr: (deprecated in c++11) An object when described using auto_ptr class it stores a pointer to a single allocated object which ensures that when it goes out
of scope, the object it points to must get automatically destroyed.
It is based on exclusive ownership model. two pointers of the same type can’t point to the same resource at the same time.
- unique_ptr: aut_ptr+improved security of no fake assignments, deleters. It is only movable. It allows exactly one owner of the underlying pointer.
When that unique_ptr is destroyed, the resource is automatically claimed. Any attempt to make a copy of unique_ptr will cause a compile-time error.
But, unique_ptr can be moved using the new move semantics i.e. using std::move() function to transfer ownership of the contained pointer to another unique_ptr.
Similar to the usage of singleton class
- shared_ptr: It is a reference counting ownership model. It is copyable and movable. It maintains the reference count of its contained pointer and adds/deletes relevently.
Use shared_ptr if you want to share ownership of a resource. Many shared_ptr can point to a single resource. It maintains reference count for this propose.
when all shared_ptr’s pointing to resource goes out of scope the resource is destroyed.
DELETE can be replaced by shared_ptr. As the pointer deallocates, when reset() is called.
Ex:
- weak_ptr: It provides access to an object that is owned by one or more shared_ptr instances but does not participate in reference counting.
It is helpful in cases like cyclic dependency problem with shared_ptr.
-> Raw pointers must be explicitly release by delete. smart pointers are automatically released.(unique_ptr). Ex: X *p = new something() - must be externally deleted.
- reset(), get(), use_count() are the functions available for the smart pointers.
Ex Ref: https://www.geeksforgeeks.org/auto_ptr-unique_ptr-shared_ptr-weak_ptr-2/
reason for smart ptr: https://www.geeksforgeeks.org/smart-pointers-cpp/
-- CAST / TypeCast:
A cast is a special operator that forces one data type to be converted into another.
Few of the cast is used to convert one pointer of another pointer of any type, no matter either the class is related to each other or not.
It does not check if the pointer type and data pointed by the pointer is same or not.
- const_cast<type> (expr) : manipulates the const or volatile variable
- dynamic_cast<type> (expr) : similar to static cast. But it is successful, only if it is of type source or else null
- reinterpret_cast<type> (expr) : usefull when working with bits for serialization. Can cast any type to any.
- static_cast<type> (expr) : simple cast works on primitive data types
-- const:
const object is created to avoid any change in the data member. const object can invoke only const member functions.
-> apply const to function param, to avoid any change in member variables
-- I/O Streams:
Headers: iostream(cin, cout, cerr, clog); iomanip(setw, setprecision), fstream.
-- File stream: fstream header supports both ifstream(reading from a file) and ofstream(creating & writing to a file).
fstream afile; afile.open("file.dat", ios::out | ios::in );
afile << (char array) for writing;
afile>>(char array for 1 word @ a time) / while(getline(afile, std::string line)-> for 1 line @ a time.
seekg for reading the position.
-- Dynamic Memory:
Memory in your C++ program is divided into two parts −
Stack − All variables declared inside the function will take up memory from the stack.
Heap − This is unused memory of the program and can be used to allocate the memory dynamically when program runs.
NEW MALLOC
calls constructor doesnot calls constructors
It is an operator It is a function
Returns exact data type Returns void *
on failure, Throws On failure, returns NULL
Memory allocated from free store Memory allocated from heap
can be overridden cannot be overridden
size is calculated by compiler size is calculated manually
Placement new :
When i already have a memory, i can use the memory to allocate buffer using placement new.
https://www.geeksforgeeks.org/placement-new-operator-cpp/
malloc is used only to create allocated buffers and not objects. However, we can use different technique to create a new object using malloc.
Link : https://stackoverflow.com/questions/2995099/malloc-and-constructors#:~:text=malloc%20does%20not%20create%20objects,use%20some%20form%20of%20new.&text=Take%20a%20look%20at%20placement,on%20a%20pre%2Dallocated%20buffer
-- Templates: Its ex of generic programming. It is a blueprint for creating a generic class or function.
Built-in containers: Iterators, algorithms, vector etc.
Function template:
template <typename> ret-type func-name(parameter list)
{ // body of function }
Example:
template <typename T> T maxNo (T a, T b)
{ return (a>b ? a:b); }
-- Templates: Its ex of generic programming. It is a blueprint for creating a generic class or function.
Built-in containers: Iterators, algorithms, vector etc.
Function template:
template <typename> ret-type func-name(parameter list)
{ // body of function }
Example:
template <typename T> T maxNo (T a, T b)
{ return (a>b ? a:b); }
in main ==> maxNo<int,int>(intVar, intVar);
The arguments are mandatory for template functions.
In C, we can also partially achieve it using the variable arguments but, it is restricted for the last argument.
Template Class:
template <class T>
class className
{ T var; T someOperation(T arg); };
Ex: Calculator for int, float etc.
Note: the use of using typename T ==> its append of typename T int (incoming param). So similarly you can also define a struct A and pass A, instead of typename T
Template Specialization:
It behaves as an except feature. Ex: write sort logic for all data types, except char.
Ref: https://www.geeksforgeeks.org/template-specialization-c/
-- Variadic templates:
Variable arguments __VA_ARGS_ are generally used in C practice. But variadic args, variadic templates are best practice in c++.
Ref: https://www.geeksforgeeks.org/variadic-function-templates-c/
Problems: If we inculde template deinition in hpp file, then "multiple definition re-defined" error is thrown by compiler. Hene, to make it as a single entry for the definition. Make the function as inline.
--LOG Mapping / OsalWrapper Trace:
If we want to re-direct the logging feature, then use the below variadic template feature.
Ex: SEND_DEBUG_LOG("hello" , "world ", 3, " welcome");
// Definition
inline void SEND_DEBUG_LOG() {}
template<typename firstArg, typename... Args>
inline void SEND_DEBUG_LOG(const firstArg& fArg, const Args&... args )
{
#ifdef DEBUG_ENABLE
std::cout << fArg << " ";
SEND_DEBUG_LOG(args...);
#else
#endif
}
-- Namespace: Used to differentiate similar classes, variables etc with same name available in different libraries.
-- getline(string) > will accept the entire line as input
cin and cout are the standard streams.
-- setprecision(no), ternary operator (?::), setw(no)
-- How to avoid Memory Leak?
- try to run static analyzer tools like coverity
- Instead of managing memory manually, try to use smart pointers where applicable.
- use std::string instead of char *. The std::string class handles all memory management internally, and it’s fast and well-optimized.
- Never use a raw pointer unless it’s to interface with an older lib.
- The best way to avoid memory leaks in C++ is to have as few new/delete calls at the program level as possible – ideally NONE. Anything that requires dynamic memory should be buried inside an RAII object that releases the memory when it goes out of scope. RAAI allocate memory in constructor and release it in destructor, so that memory is guaranteed to be deallocated when the variable leave the current scope.
- Allocate memory by new keyword and deallocate memory by delete keyword and write all code between them.
- Memory allocated on heap should always be freed when no longer needed.
- use copy constructor and assignment operator to avoid memory leak and
-- Serialization & Deserialization
* Modifying the data to the non-readable format and hiding is meant to be as a Encryption
* But breaking the chunks of data and re-framing at the other end or vice-versa frames as serialization and de-serialization.
* Example: User input is 32bit(uint32_t) and someip can transfer only 8bit. then we need to serialize and split this is an array and send it and re-transform back in the destination.
-- CALLBACK FUNCTIONS:
A callback is any executable code that is passed as an argument to other code, which is expected to call back (execute) the argument at a given time.
- Functors in the c++ is same as callback functions.
- Transform: Perform an operation on all elements of the data structures.
Ex: (1) Declare the function -> func()
(2) Assign the func to pointer. (ret-type) (*ptr)(arg-list) = &func;
(3) pass the ptr to different function if needed. start(ptr)
(4) receive as arg in the function. void start(int (*ptr)(int num))
And call the func() like (*ptr)(args)
- In c++, while using a callback, it sometimes throws an error. "Invalid use of non-static member". Don’t get deviate with using the static member, instead use "std::bind and associate the object.
std::bind(&classname::func, this, std::placeholders::_1, etc)
BIND: The function template bind generates a forwarding call wrapper for f.
Calling this wrapper is equivalent to invoking f with some of its arguments bound to args.
typdef -> function pointer.
The callback can also be achieved using typedef. print_to_n(int) is a function.
typedef void (*printer_t)(int); ==> printer_t p = &print_to_n; ==> p(5);
-- BITWISE OPERATIONS PGM:
Bit operators: & | >> << ~ ^
-- DATA STRUCTURES
VECTOR: Vectors are same as dynamic arrays with the ability to resize itself automatically when an element is inserted or deleted, with their storage being handled automatically by the container
std::vector <data-type> vec -> vec.push_back/insert -> std::vector<data-type>::iterator i = vec.begin() & i!= vec.end()->print *i;
vector.reserve(size) is the function to preserve the vector from changing the memory address and resizing.
MAP: Maps are associative containers that store elements in a mapped fashion.
Each element has a key value and a mapped value. No two mapped values can have same key values.
std::map<int,int> mp; -> mp.insert(std::pair<int,int>(1,2)) -> std::map<int,int>::iterator i =mp.begin()&i!=mp.end() --> i->first, i->second
There are 3 types of map supported in c++
* regular map ==> std::map -> ordered map with single skey concept
* multi map ==> std::multimap -> allows multiple values for a single key
* unordered_map / hash map ==> std::unordered_map -> allows map entry with no assurance for the order.
collision in map: this is the collision compiler faces, for storing the same values for a different key.
However, this collision chaining is implemented in unordered_map.
Linked LIST: Lists are sequence containers that allow constant time insert and erase operations anywhere within the sequence, and iteration in both directions. The main drawback of lists and forward_lists compared to these other sequence containers is that they lack direct access to the elements by their position
std::list <data-type> name; rest other functions remain same
List vs Vectors:
https://thispointer.com/difference-between-vector-and-list-in-c/#:~:text=Both%20vector%20and%20list%20are%20sequential%20containers%20of%20C%2B%2B%20Standard%20Template%20Library.&text=List%20stores%20elements%20at%20non,locations%20like%20an%20array%20i.e.
https://www.geeksforgeeks.org/difference-between-vector-and-list/
ARRAY: An array in C or C++ is a collection of items stored at contiguous memory locations and elements can be accessed
randomly using indices of an array. Same as C arrays.
STRING: std::string is a class and not a data-type. while printing use var.c_str()
you can access whole string or each character at a time. '+' operator function is implemented by default.
Hence, str1+str2 is allowed.
-- String: array of characters: Ref: https://www.geeksforgeeks.org/stdstring-class-in-c/
PROCESS VS THREADS:
-- A process is a program under execution i.e an active program.
consume more time for execution and context switch as it is heavy.
Processes have independent data and code segments.
-- A thread is a lightweight process that can be managed independently by a scheduler.
consume less time for execution and context switch as it is lightweight.
A thread shares the data segment, code segment, files etc. with its peer threads.
thread: std::thread th(function) -> if calling from main.
std::thread th = std::thread(&classname::function name, this);
dont forget to do this.joinable() { th.join() }; -> or else the app crashes.
DETACH: Detaches the thread represented by the object from the calling thread, allowing them to execute independently from each other.
JOIN: The function returns when the thread execution has completed.
This synchronizes the moment this function returns with the completion of all the operations in the thread: This blocks the execution of the thread that calls this function until the function called on construction returns. After a call to this function, the thread object becomes non-joinable and can be destroyed safely.
JOIN:Blocks the current thread until the thread identified by *this finishes its execution.
The completion of the thread identified by *this synchronizes with the corresponding successful return from join().
In C98, we have used thread with help of start() and run() functions.
Diff for vector and template ==> vector is a template which accepts different data-type. Template is a collection creator.
Diff for vector and Array ==> vector is a sequential container to store elements and not index based and dynamic in size decrease/increase.
Array stores a fixed-size sequential collection of elements of the same type and it is index based and fixed size, once initialized can't be resized.
-- CONDITIONAL VARIABLES:
Condition Variable: Is an object able to block the calling thread until notified to resume.
It uses a unique_lock (over a mutex) to lock the thread when one of its wait functions is called. The thread remains blocked until woken up by another thread that calls a notification function on the same condition_variable object.
Example:
std::mutex mtx; std::condition_variable cv;
thread - func { std::unique_lock<std::mutex> lck(mtx); while (!ready) cv.wait(lck); }
func2 { cv.notify_all(); }
Supporting functions:
wait(lck), wait_for(lck,timeout,func()), wait_untill(lck,timeout), notify_one(), notify_all()
-- LOCKS
-> Mutex lock:
A mutex is a lockable object that is designed to signal when critical sections of code need exclusive access, preventing other threads with the same protection from executing concurrently and access the same memory locations.
Supporting functions: lock, unlock, try_lock, native_handle
-> std::lock(lck1, lck2, ...)
-> std::lock_guard : An object that manages a mutex object by keeping it always locked, unlocked when out of scope
-> std::unique_lock: can be created without immediately locking, can unlock at any point in its existence, and can transfer ownership of the lock from one instance to another.
Use lock_guard unless you need to be able to manually unlock the mutex in between without destroying the lock. In particular, condition_variable unlocks its mutex when going to sleep upon calls to wait. That is why a lock_guard is not sufficient here.
-> std::call_once: Calls fn passing args as arguments, unless another thread has already executed (or is currently executing) a call to call_once with the same flag.
-> std::shared_lock: Used in conjunction with a unique lock to allow multiple readers and exclusive writers.
-> std::recursive_mutex: A lockable object, just like mutex, but allows the same thread to acquire multiple levels of ownership over the mutex object.
-> std::recursive_timed_mutex: Combines both the features of recursive_mutex and the features of timed_mutex into a single class. It supports both acquiring multiple lock levels by a single thread and also timed try-lock requests.
Combo supporters: {defer_lock, try_to_lock, adopt_lock}
https://riptutorial.com/cplusplus/example/30439/strategies-for-lock-classes--std--try-to-lock--std--adopt-lock--std--defer-lock
Automicity : It is unbreakability, i.e. an uninterrupted operation.
To ensure, the sequence of instructions is executed in a expected order.
Critical Section:
When more than one processes access a same code segment that segment is known as critical section.
It contains shared variables or resources which are needed to be synchronized to maintain consistency of data variable. It contains the each instructions which attempts for automicity.
semaphore
Semaphore is simply a variable that is non-negative and shared between threads. A semaphore is a signaling mechanism, and a thread that is waiting on a semaphore can be signaled by another thread. It uses two atomic operations, 1)wait, and 2) signal for the process
synchronization.
-> we have 2 types of semaphores. Counting semaphore, binary semaphore.
-> Its a conceptual realization of synchronizing the critical section
Mutex vs Semaphore :
Mutex is a lock and only one access to a resource is available at any point of time. Whereas, semaphore works on signalling on the availability.
Mutex is a locking mechanism whereas Semaphore is a signaling mechanism
Mutex is just an object while Semaphore is an integer
Mutex has no subtype whereas Semaphore has two types, which are counting semaphore and binary semaphore.
Semaphore supports and values are modified using wait and signal operations modification,
whereas Mutex is only modified by the process that may request or release a resource. Mutex is either locked or unlocked.
Semaphore allow multiple program threads to access a finite instance of resources. Mutex allow multiple program thread to access a
single resource but not simultaneously.
Use of Semaphore
In the case of a single buffer, we can separate the 4 KB buffer into four 1 KB buffers. Semaphore can be associated with these four
buffers. This allows users and producers to work on different buffers at the same time.
Use of Mutex
A mutex provides mutual exclusion, which can be either producer or consumer that can have the key (mutex) and proceed with their work. As
long as producer fills buffer, the user needs to wait, and vice versa. In Mutex lock, all the time, only a single thread can work with the
entire buffer.
Refer the general questions in below link.
https://www.geeksforgeeks.org/mutex-vs-semaphore/
-- Explicit keyword:
The keyword ensures, the conversion constructor is compared against the restricted type.
Ex: Complex == 3.0 can be avoided . ==> complex typecast is expected
https://www.geeksforgeeks.org/g-fact-93/
-- SERILIZATION & DE-SERILIZATION :
These are the mechanisms to write/construct the data to a file/buffer/socket which ever is supported for the transfer.
There are different mechanisms to safely serialize and de-serialize. Ex: shift operator, memory assignment.
PEEK and POKE are commands used for accessing the contents of a specific memory cell referenced by its memory address.
PEEK gets the byte located at the specified memory address. POKE sets the memory byte at the specified address.
One exampe is as below.
// serialization
void poke(uint8_t * const buffer, const float & value)
{ uint8_t * valuePtr = reinterpret_cast<uint8_t*>(const_cast<float*>(&value));
buffer[0] = valuePtr[0]; buffer[1] = valuePtr[1]; buffer[2] = valuePtr[2]; buffer[3] = valuePtr[3]; }
// de-serialize
void peek(uint8_t const * const buffer, float & value)
{ uint8_t * valuePtr = reinterpret_cast<uint8_t*>(&value);
valuePtr[0] = buffer[0]; valuePtr[1] = buffer[1]; valuePtr[2] = buffer[2]; valuePtr[3] = buffer[3]; }
// main
float val = 75.347; uint8_t buffer[4];
poke(buffer, val); // buffer[0],buffer[1],buffer[2],buffer[3] are the payload to be sent to other side
peek(buffer, val);
sample values
76000.000000 (dec)00 112 148 71
70000.000000 (dec)00 184 136 71
71000.000000 (dec)00 172 138 71
-- INTERRUPTS VS SIGNALS:
Signals(between the OS kernel and OS processes) are similar to interrupts(between the CPU and the OS kernel),
the difference being that interrupts are mediated by the processor and handled by the kernel
while signals are mediated by the kernel (possibly via system calls) and handled by processes.
Interrupts may be initiated by the CPU (exceptions - e.g.: divide by zero, page fault), devices (hardware interrupts - e.g: input
available), or by a CPU instruction (traps - e.g: syscalls, breakpoints). They are eventually managed by the CPU, which
"interrupts" the current task, and invokes an OS-kernel provided ISR/interrupt handler.
Signals may be initiated by the OS kernel (e.g: SIGFPE, SIGSEGV, SIGIO), or by a process(kill()). They are eventually managed by
the OS kernel, which delivers them to the target thread/process, invoking either a generic action (ignore, terminate,
and dump core) or a process-provided signal handler.
signal(signal_name, signalFunctionName) -> used to register the catch function for the signal_name
raise(signal_name) -> used to trigger the signal passed to the function
Timers on interrupt:
S/w vs Hw - Software timers are more error ratio when comparitive to the hardware error ratio.
Both works on concept of the interrupt. In s/w interrupt, the time consumed on executing the task is more compared to the h/w interrupt
Ex: kernel time is more error prone, compared to the hardware RTC chip time.
-- DESIGN PATTERNS:
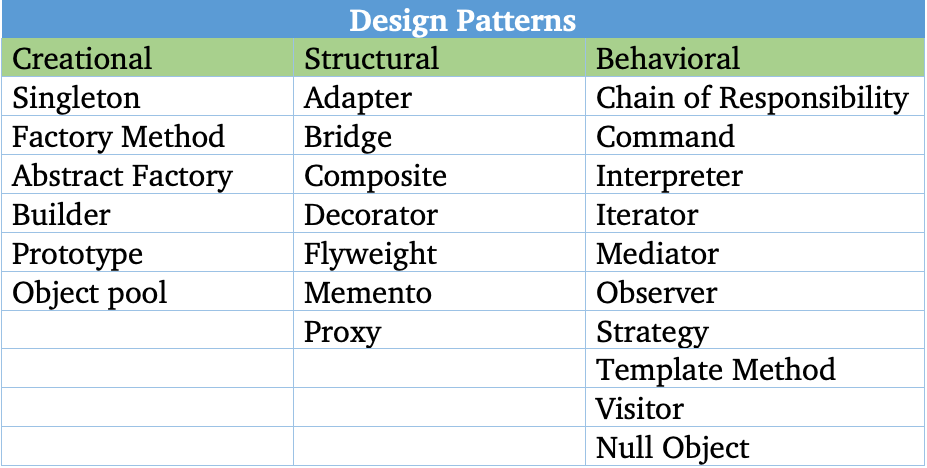
SINGLETON: used to restrict the instantiation of a class to one object.
Ex: class Singleton { private: constructor(); static Singleton *instance;
public:static Singleton *getInstance() { if (!instance) instance = new Singleton; return instance; }
after class & before main -> single *single::instance = 0;
main() { single *s = s->getInstance(); }
Destructing Singleton Object: It is dangerous to call delete for the singleton object. This might trigger to a recursive call. But, some compilers also help to notify user by restricting the call of delete <singletonObject>. However, we can destruct the singleton object with the help of static function destroy and call delete utside the destructor like main.
Ref: https://stackoverflow.com/questions/8699434/how-to-delete-singleton-pointer/8699599
FACADE CLASS:
A "facade" object provides a single, simplified interface to the many, potentially complex, individual interfaces within the subsystem.
Ex: HouseFacade hf; hf.go_to_work(); hf.come_home();
above are the 2 functions just called to achieve multi functions like ac, tv, water. Ac()(off/on states )etc are common functions accessible.
Ref: http://www.vishalchovatiya.com/facade-design-pattern-in-modern-cpp/
-- IPC MECHANISMS:
Inter Process Communication (IPC) is a mechanism that involves communication of one process with another process.
keyword DUPLEX: able to send / receive data.
PIPES(half duplex), FIFO'S(full duplex), Message Queues, Shared Memory.
IPC SYSTEMS / RPC :
Vsomeip
D-bus -- Its a software bus used for ipc. D-BUS is an interprocess communication (IPC) system, providing a simple yet powerful mechanism allowing applications to talk to one another,
communicate information and request services.
sd-bus -- systemd d-bus. with extra features like ssh, credntial model etc.
THRIFT -- Thrift is an interface definition language and binary communication protocol used for defining and creating services for numerous programming languages. It forms a remote procedure call (RPC) framework.
vsomeip -- vsomeip is a genivi developed software rpc framework.
-- INLINE FUNCTIONS:
Inline function:
Inlining is only a request to the compiler, not a command.
Compiler can ignore the request for inlining. Compiler may not perform inlining in such circumstances like:
1) If a function contains a loop. (for, while, do-while)
2) If a function contains static variables.
3) If a function is recursive.
4) If a function return type is other than void, and the return statement doesn’t exist in function body.
5) If a function contains switch or goto statement.
Inline functions provide following advantages:
1) Function call overhead doesn’t occur.
2) It also saves the overhead of push/pop variables on the stack when function is called.
3) It also saves overhead of a return call from a function.
4) When you inline a function, you may enable compiler to perform context specific optimization on the body of function. Such optimizations are not
possible for normal function calls. Other optimizations can be obtained by considering the flows of calling context and the called context.
5) Inline function may be useful (if it is small) for embedded systems because inline can yield less code than the function call preamble and return.
6) If function definition is in hpp, the "redefinition / multiple declaration" error occurs. So, mark the function as inline.
Inline function disadvantages:
1) The added variables from the inlined function consumes additional registers, After in-lining function if variables number which are going to use
register increases than they may create overhead on register variable resource utilization.
2) If you use too many inline functions then the size of the binary executable file will be large, because of the duplication of same code.
3) Too much inlining can also reduce your instruction cache hit rate, thus reducing the speed of instruction fetch from that of cache memory to that of
primary memory.
4) Inline function may increase compile time overhead if someone changes the code inside the inline function then all the calling location has to be
recompiled because compiler would require to replace all the code once again to reflect the changes, otherwise it will continue with old functionality.
5) Inline functions may not be useful for many embedded systems. Because in embedded systems code size is more important than speed.
6) Inline functions might cause thrashing because inlining might increase size of the binary executable file. Thrashing in memory causes performance of
computer to degrade.
Recursion function as inline :
The recursive function can be marked as a inline. but if the function has more depth, probably the compiler might reject it. however, the depth can be restricted again using pragma "--max-inline-insns-recursive"
Recursion vs interation/looping
Recursion functions are faster than iterations in case of functional programming languages.
They have ease access to the callstack member variables.
Functional programming languages are specially designed to handle symbolic computation and list processing applications. Functional
programming is based on mathematical functions. Some of the popular functional programming languages include: Lisp, Python, Erlang,
Haskell, Clojure, etc.
Functional programming languages vs OOPS :
https://www.tutorialspoint.com/functional_programming/functional_programming_introduction.htm
-- ALGORITHMS :
https://www.geeksforgeeks.org/fundamentals-of-algorithms/#SearchingandSorting
-- Searhing and Sorting + Complexity:
https://www.geeksforgeeks.org/time-complexities-of-all-sorting-algorithms/
-- Socket Communication :

-- BIT Manipulation :
-> right shift to remove unnecessary bits
-> left shift 1 to get te power of 2 & extract particular bit
-> use ((1<<n)-1) for masking all the bits of power of 'n' . Ex: (1<<5)-1 = 31 ==> 11111
-> use (1<<n) for masking particular bit Ex: 1<<5 = 100000
-> use ~(1<<n) for masking 0 to a particular bit Ex: ~(1<<5) = 111011111
-> use XOR for toggling the bit
-> use ~ to negate all the bits
-> possible operations : << , >> , | , & , ~ , ! , ^
-> if last bit of a digit is 1 ==> odd else even.
-> XOR : Returns 1 for different bit values and 0 for same bit values.
-> Little endian -> starts the bit representation from left, and Big endian=>right most
[Can use union to find out, whether it is little / big endian]
-> To check the set bits in a integer : while (n) { n &= (n - 1); count++;}
Extract the bits
for (int i = 0; i < 8; i++) {
// Mask each bit in the byte and store it
bits[i] = byte & 1;
byte >>= 1;
}
Bit manipulation useful pgms :
https://medium.com/techie-delight/bit-manipulation-interview-questions-and-practice-problems-27c0e71412e7
-- EXTRA:
-> #pragma once - will let us to declare the headers in more than one file, but intimates the compiler not to warn
-> We have digit separator, binary literals (0b/0B), auto return type in functions.
-> static_assert will help us to check the assert at compile time
-> along with class types like string, class we can also define template variable. template specialization is available.
-> [[deprecated("some message")]] - will help compiler to inform the next function code block should not be compiled. however, a warning will be generated.
-> Lambda: it is similar to inline functions. just like ternary operator is a replacement for the if clause, lambda helps to replace a mini functions in validating any data or calling to return any value.
Ex: int m = 8; auto x = [m](int a){return m/a;}; cout <<" x = " << x(2);
-> Whitespace: In ASCII, whitespace characters are space (' '), tab ('\t'), carriage return ('\r'), newline ('\n'), vertical tab ('\v') and formfeed ('\f').
-> Data Types: character, integer, float, and void are fundamental data types. Pointers, arrays, structures and unions are derived data types.
-> typedef and #define works almost same with few minor diff
-> Unary operator: formed with single operator(+, -, !, ~, &, *, ++, --, sizeof, cast, offsetof) with one operand
-> ## is used as a concatenation for pre-processor declaration. it clubs the number/string
-> sizeof() will return the size of data type in bytes. offsetof(type, member-designator) will return the size_t which is the offset in bytes of the structure member, starting from the beginning of the structure.
-> void* is like a c template. it accepts any type of casting conversion. Ex: swap function to accept different parameters. you can use void* as parameters. void *p1; int a = *(int*)p1;
-> variable number of arguments
https://stackoverflow.com/questions/1657883/variable-number-of-arguments-in-c
-- TEST FRAMEWORK
Google test is the common test suite model generally used for the small project. Gtest test-suite also provides the test framework to adapt for the extended project with the code coverage and report.
However, similar to the gtest framework. We can club the gtest test suite with the finao framework and generate the code coverage and the report.
Macros details that can be used in GTEST :
https://github.com/google/googletest/blob/master/googletest/docs/primer.md
INTERVIEW QUESTIONS:
- -
- -
Referrences:
Tutorial: https://www.tutorialspoint.com/cplusplus/
CPP standard: https://isocpp.org/
Useful link http://www.cplusplus.com/reference/algorithm/
Useful link http://www.cplusplus.com/reference/
(Font used: Times)